
So… I’ve been working on a new project the past few days, coding a virtual assistant in Python. The idea began simply enough, I could automate certain tasks in my lab space via voice commands. For example, instead of writing lab notes why not dictate them to my computer. Well, it wasn’t long after I started working on the code that the project began to morph into something bigger.


It started when I began realizing, that in order to make this work, I need to consider the context of the speech. For example, it is natural for us to say(our end goal, a system which feels natural to use), “find the meaning of mathematics” or “find x squared plus 3 x minus 2, where x is 4;” but, they both have very different and unique expectations. “Find the meaning of mathematics” expects a definition; where as, “find x squared plus 3 x minus 2, where x is 4” expects a solution to “x^(2)+3x-2, x=4”. So here we have two very different expectations, both with their own unique set of rules for how those expectations can/should be addressed. It was with this realization, that I began to see the need to branch out into the world of machine learning. So, I set forth to Google armed with only my curiosity and a rough version of my program.
See so far I could make “computer Google machine learning” work, but without extra coding how could I make, “computer search for…, computer find…,” or even “computer what is…” work? Well, as it turns out, there are a couple different libraries/modules for Python that can help tackle this problem, Natural Language Tool Kit(NLTK) and Tensor Flow to name two. So, I know I can handle this problem now… But I bet I could create a chatbot while I’m at it. More over, wouldn’t it be cool if the chatbot could also recognize you, and respond accordingly? And so, here I am… piecing together code and writing new code in order to make my digital chatbot assistant.
With that said, let’s begin looking at the code.

Pt 1, the base code of the command section.
Command_BaseCode.py:
#######################################################################################################################
# [1]
#
# Author:
# Matt Tucker
#
# Date:
# 8Aug2017-
#
# Description:
# The following is only part of a chatbot that will analyze visual information to identify users, create user
# profiles, imitate a personality based on user, while also acting as a virtual assistant via executing
# a handful of basic commands.
#
# This particular part handles the commands as they are given to the computer.
# ToDo: Create a context sensitive translation... Ex: "Get the weather." -> "What is the weather?"
#######################################################################################################################
import speech_recognition as sr
from time import ctime
from gtts import gTTS
from playsound import playsound
import webbrowser
import os
import re
import wolframalpha
import wikipedia
import smtplib
import time
import pyowm
from twilio.rest import TwilioRestClient
from PyDictionary import PyDictionary
# Keys and other user specific information
pw = "GMail PW"
add = "GMail Address"
location = "City, State"
signature = '\n' + "Name" + '\n' + "This was written via "pronoun" digital assistant"
client = wolframalpha.Client("Get Your Own")
owm = pyowm.OWM('Get Your Own')
account = "Get Your Own"
token = "Get Your Own"
client1 = TwilioRestClient(account, token)
# Replace symbols with "math jargon." To be used in calculation command!
def clean_text(text):
text = re.sub(r" ", "", text)
text = re.sub(r"first", "1 ", text)
text = re.sub(r"second", "2 ", text)
text = re.sub(r"third", "3 ", text)
text = re.sub(r"forth", "4 ", text)
text = re.sub(r"fifth", "5 ", text)
text = re.sub(r"sixth", "6 ", text)
text = re.sub(r"seventh", "7 ", text)
text = re.sub(r"eighth", "8 ", text)
text = re.sub(r"ninth", "9 ", text)
text = re.sub(r"tenth", "10 ", text)
text = re.sub(r"1st", "1 ", text)
text = re.sub(r"2nd", "2 ", text)
text = re.sub(r"3rd", "3 ", text)
text = re.sub(r"4th", "4 ", text)
text = re.sub(r"5th", "5 ", text)
text = re.sub(r"6th", "6 ", text)
text = re.sub(r"7th", "7 ", text)
text = re.sub(r"8th", "8 ", text)
text = re.sub(r"9th", "9 ", text)
text = re.sub(r"0th", "0 ", text)
text = re.sub(r"/", "/", text)
text = re.sub(r"-", "-", text)
text = re.sub(r"=", "=", text)
text = re.sub(r"isequalto", "=", text)
text = re.sub(r"is", "=", text)
text = re.sub(r"equalto", "=", text)
text = re.sub(r"equals", "=", text)
text = re.sub(r"over", "/", text)
text = re.sub(r"divide", "/", text)
text = re.sub(r"times", "*", text)
text = re.sub(r"multiply", "*", text)
text = re.sub(r"plus", "+", text)
text = re.sub(r"add", "+", text)
text = re.sub(r"subtract", "-", text)
text = re.sub(r"minus", "-", text)
text = re.sub(r"squared", "^2 ", text)
text = re.sub(r"tothe", "^", text)
text = re.sub(r"sign", "sin", text)
text = re.sub(r"cosign", "cos", text)
text = re.sub(r"sine", "sin", text)
text = re.sub(r"cosine", "cos", text)
text = re.sub(r"power", "", text)
text = re.sub(r"where", ", where ", text)
text = re.sub(r"for", ", for ", text)
return text
# Responsible for vocalising responses
def speak(audioString):
# This is only here to aid in problem solving, "did it hear me correctly?"
print(audioString)
tts = gTTS(text=audioString, lang='en-uk')
tts.save("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
# Responsible for "listening to" and returning the users comments
def recordAudio():
# Record Audio
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
# speak("I'm listening")
audio = r.listen(source)
# Speech recognition
data = ""
try:
data = r.recognize_google(audio)
if data == "end program":
speak("Goodbye!")
exit()
# This is only here to aid in problem solving, "did it hear me correctly?"
print("You said: " + data)
except sr.UnknownValueError:
speak("Can you please repeat that")
recordAudio()
except sr.RequestError as e:
speak("Can you please repeat that?".format(e))
recordAudio()
data = data.lower()
return data
# This is the function responsible for executing commands
def command(data):
# Request time
if "time" in data:
speak(ctime())
# Request map info
if "show me where a city is" in data:
speak("Sure thing Mathew, what is the name of the city?")
city = recordAudio()
speak("Now, what state is it in?")
state = recordAudio()
speak("Hold on Mathew, I will show you where " + city + ", " + state + " is.")
speak("chromium-browser https://www.google.us/maps/place/" + city + "," + state + "/&")
# Request data search
if ("google" or "search") in data:
data = data.split("Google " or "search ")
search = " ".join(str(x) for x in data)
speak("Googling " + search)
url = "https://www.google.co.in/search?q=" + search + "&oq=" + search + "&gs_l=serp.12..0i71l8.0.0.0.6391.0.0.0.0.0.0.0.0..0.0....0...1c..64.serp..0.0.0.UiQhpfaBsuU"
webbrowser.open_new(url)
# Resquest calculations be done
if ("calculate" or "find") in data:
if "calculate" in data:
data = data.split("calculate ")
else:
data = data.split("find ")
search = " ".join(str(x) for x in data)
_search = clean_text(search)
speak("Calculating " + _search)
try:
res = client.query(_search)
answer = next(res.results).text
speak(answer)
except:
speak("Sorry, I was unable to get an answer for you")
# Request info from Wikipedia
if "tell me about" in data:
data = data.split("tell me about ")
search = " ".join(str(x) for x in data)
speak("Searching...")
try:
res = (wikipedia.summary(search))
speak("Sir, I found " + data + " for you: " + res)
except:
speak("I was unable to find anything")
# Get weather
if "weather" in data:
data = data.split("weather")
search = " ".join(str(x) for x in data)
if "today" in search:
fc = owm.weather_at_place(location)
w = fc.get_weather()
else:
fc = owm.daily_forecast(location, limit=3)
w = fc.get_weather()
client1.messages.create(from_='(507) 607-7398', to='(507) 382-0499', body = ('\n' + "Here's the forecast you requested:" + '\n' + w.get_detailed_status()+ '\n' + str(w.get_temperature('fahrenheit'))))
# Request an email be written and sent
if ("email") in data:
speak("Certainly sir, who would you like me this to?")
targ = recordAudio()
speak("What would you like to say in your email sir?")
mat = recordAudio()
mail = smtplib.SMTP('smtp.gmail.com', 587)
try:
mail.ehlo()
except:
mail.helo()
mail.starttls()
mail.login(add, pw)
mail.sendmail(add, targ, mat)
mail.close()
# Request definition, synonym, or antonym
if "definition" in data:
data = data.split("definition of")
search = " ".join(str(x) for x in data)
dictionary = PyDictionary()
speak(str((dictionary.meaning(search))))
if "synonym" in data:
data = data.split("synonym of")
search = " ".join(str(x) for x in data)
dictionary = PyDictionary()
speak(str((dictionary.synonym(search))))
if "antonym" in data:
data = data.split("definition of")
search = " ".join(str(x) for x in data)
dictionary = PyDictionary()
speak(str((dictionary.antonym(search))))
# ToDO #########################################################################
# ToDO # #
# ToDO # Add dictation. Remember to offer a few locations to store file. #
# ToDO # #
# ToDO #########################################################################
# Request a program be opened, use similar process to take down dictations in .txt file but it will nee a seperate
# calling to recordAudio for what it types.
if "open" in data:
data = data.split("open ")
program = " ".join(str(x) for x in data)
speak("Opening " + program)
# Special note, use: os.system("open -a path/program.app") to open program so it should look like:
# if "name" in program:
# os.system("open -a path/name.app")
if "iTunes" in program:
os.system("open -a program.app")
if "Matlab" in program:
os.system("open -a MATLAB_R2017a.app")
if "VLC" in program:
os.system("open -a program.app")
if "slicer" in program:
os.system("open -a Slic3r.app")
if "pycharm" in program:
os.system("open -a 'PyCharm CE.app.app'")
if "ip scanner" in program:
os.system("open -a 'IP Scanner.app'")
if "Arduino" in program:
os.system("open -a Arduino.app")
if "eclipse" in program:
os.system("open -a Eclipse.app")
if "AutoCad" in program:
os.system("open -a 'AutoCAD 2016.app'")
if "terminal" in program:
os.system("open -a Terminal.app")
if "latex" in program:
os.system("open -a texmaker.app")
# Opens a file that acts as a list of impromptu commands
if "new command" in data:
speak("Remember, you have to type this for yourself. I can't type it for you.")
os.system("open -a '/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/command.txt'")
# Searches file of impromptu commands for correct command
else:
coms = open("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/command.txt", "r")
for line in coms:
if re.match(data, line):
os.system(next(coms))
else:
speak("I'm sorry, I can't do that.")
coms.close()
# Where the magic happens...
def init():
while 1:
data = recordAudio()
# Exit commands
if "that will be all" in data:
speak("Certainly sir.")
break
if "no" in data:
speak("Certainly sir.")
break
if "thank you for your help" in data:
speak("Certainly sir.")
break
# Operation Commands
else:
command(data)
data = ""
speak("will there be anything else sir?")
# Initialization...
time.sleep(1)
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/Computer_Magic-Microsift-1901299923.mp3")
while 1:
speak("Hello Mathew, what can I do for you?")
init()
Pt 2., the base code for the facial recognition section…(Still under construction)
FacialRecognition_BaseCode.py
#######################################################################################################################
# [2]
#
# Author:
# Matt Tucker
#
# Date:
# 9Aug2017-
#
# Description:
# The following is only part of a chatbot that will analyze visual information to identify users, create user
# profiles, imitate a personality based on user, while also acting as a virtual assistant via executing
# a handful of basic commands.
#
# This particular part handles the facial recognition procedure.
#
# Note of Acknowledgement:
# This program was built using the Facial Recognition example from,
# "http://rpihome.blogspot.com/2015/03/face-detection-with-raspberry-pi.html" as a base/outline. As such much
# of the basic underlining structure may appear similar or even be the same. And for that reason, I would
# like to extend a thank you to the author.
#
# ToDo: This program needs to be modified to work with RPi and with video.
#######################################################################################################################
import cv2
i = 1
while i < 5:
title = "faces/" + str(i) + ".jpeg"
# Load an image from file
image = cv2.imread(title, 1)
# Load a cascade file for detecting faces
face_cascade = cv2.CascadeClassifier('haarcascade/haarcascade_frontalface_alt.xml')
# Convert to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Look for faces in the image using the loaded cascade file
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
print "Found "+str(len(faces))+" face(s)"
# Draw a rectangle around every found face
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
# Adds text to the image
# Come back to this later and improve description
cv2.putText(image, "Image: " + str(i), (0, 10), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 2, 8, bottomLeftOrigin = False)
# Save the result image
result = "results/result" + str(i) + ".jpg"
cv2.imwrite(result, image)
i += 1
Here is an example of the input-output:


Pt 3.1 the chatbot section. This part of the code is still in flux. This is a test of one chatbot recipe. There will be others until I decide on one, which will be named Chatbot_BaseCode.py
#######################################################################################################################
# [3_1]
#
# Author:
# Matt Tucker
#
# Date:
# 14Aug2017-
#
# Description:
# The following is only part of a chatbot that will analyze visual information to identify users, create user
# profiles, imitate a personality based on user, while also acting as a virtual assistant via executing
# a handful of basic commands.
#
# This particular part handles the ChatBot.
#
# Author's Note:
# I'm using this to test out different approaches to creating a Chatbot before I commit to a chat bot to be
# used in "ChatBot_BaseCode.py".
#######################################################################################################################
from gtts import gTTS
from playsound import playsound
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
# Responsible for vocalising responses
def speak(audioString):
# This is only here to aid in problem solving, "did it hear me correctly?"
print(audioString)
tts = gTTS(text=audioString, lang='en-uk')
tts.save("srcs/audio.mp3")
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
chatbot = ChatBot("Tod")
chatbot.set_trainer(ListTrainer)
chatbot.train("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/trainingdata.txt")
print "Moving to response now..."
response = str(chatbot.get_response("What is death?"))
speak(response)
As a funny note, I appeared to have turned my computer into Marvin from The Hitchhiker’s Guide to the Galaxy using this code:
So after rewriting the chatbot code, and re-editing the format of the training data, this is what I got:
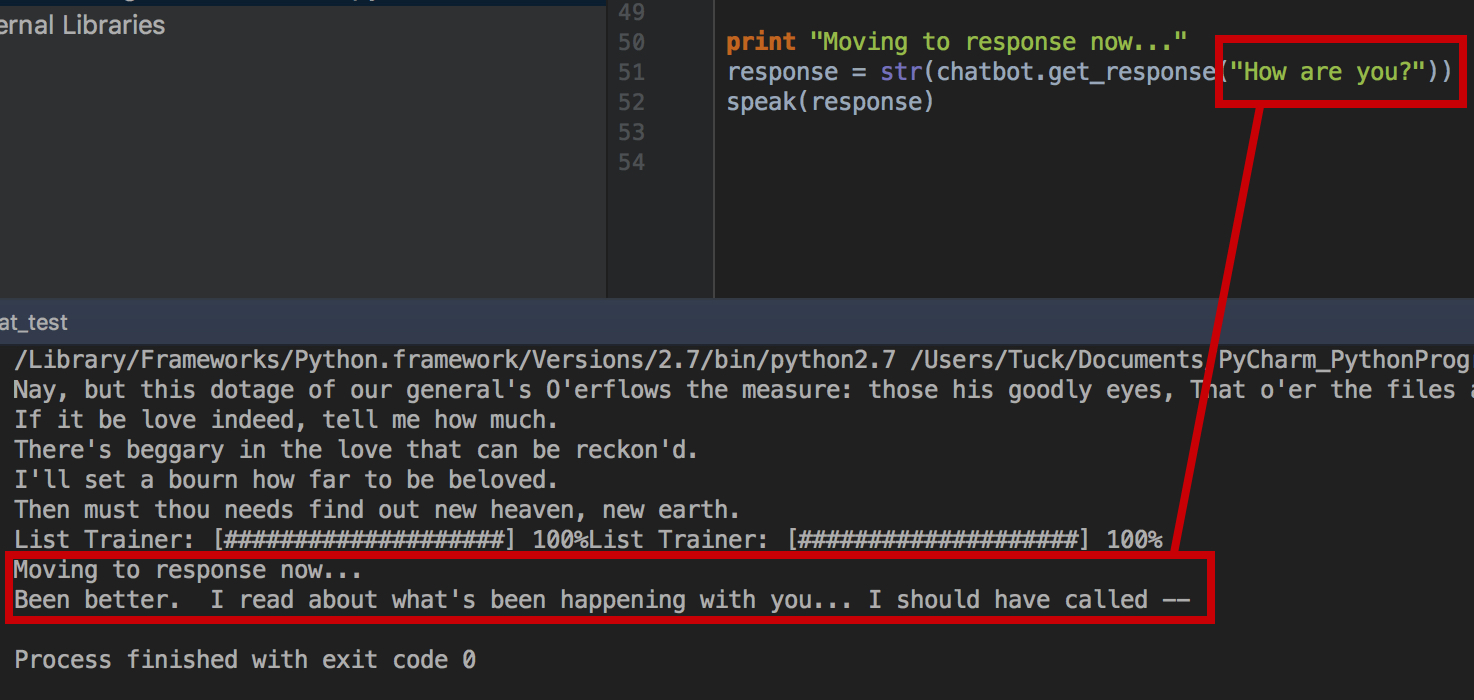
Pt 3.2
#######################################################################################################################
# [3_2]
#
# Author:
# Matt Tucker
#
# Date:
# 14Aug2017-
#
# Description:
# The following is only part of a chatbot that will analyze visual information to identify users, create user
# profiles, imitate a personality based on user, while also acting as a virtual assistant via executing
# a handful of basic commands.
#
# This particular part handles the ChatBot.
#
# Author's Note:
# I'm using this to test out different approaches to creating a Chatbot before I commit to a chat bot to be
# used in "ChatBot_BaseCode.py".
#######################################################################################################################
from gtts import gTTS
from playsound import playsound
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
f_1 = open('/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/trainingdata.txt')
# f_1 = open('/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/clean_trainingdata.txt')
lines_1 = [line.rstrip('\n') for line in f_1]
i=0
while i in range(5):
print lines_1[i]
i += 1
# Responsible for vocalising responses
def speak(audioString):
# This is only here to aid in problem solving, "did it hear me correctly?"
print(audioString)
tts = gTTS(text=audioString, lang='en-uk')
tts.save("srcs/audio.mp3")
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
chatbot = ChatBot("Frank")
chatbot.set_trainer(ListTrainer)
chatbot.train(lines_1)
print "Moving to response now..."
response = str(chatbot.get_response("How are you?"))
speak(response)
I will be back at a later date to better explain what the code is doing, and some of the theory behind, as well as expanding on how everything will go together. I will also be posting the code on GitHub when I am done with it.
27Aug17
So, as promised I’m back… To explain the code as well as point out some hiccups -e.g. you might have already noticed the face recognition isn’t quite what we want.
Let’s start with Pt. 1 the base code for the command portion:
In order to expedite the explanation of the code; I will leave it up to the reader to look up the different libraries and APIs used so that they can better understand them/use them. This includes how to get keys and tokens.
So, let’s start with,
import re
...
def clean_text(text):
text = re.sub(r"first", "1 ", text)
text = re.sub(r"second", "2 ", text)
...
return text
Here we are importing the regular expressions module and using the “sub” operation to replace text in our string. For example,
text = re.sub(r"second", "2 ", text)
...
return text
takes our input “text” and searches for “second,” replace it with “2 ” in our output “text,” and finally after it runs thru the other “sub” operations it returns our “fixed” input “text.”
output = re.sub(r"thing to be replaced", "thing to take its place", input)
This is great an all, but why use it? Well, for a number of reasons… In particular, here we’re using it for pre formatting text so that when we get ready to pass it to another function/operation later, it will be useable. For example, we pass spoken words to WolframAlpha’s API to get calculations. So imagine you want to know, “the integral of x squared dx is what?” We should probably write that in a bit better format for Wolfram… like… “the integral of x^2 dx is what?” (Disclaimer: After some digging… I’m not entirely sure that this is actually needed. I was incredibly hard pressed to find a case where Wolfram didn’t work with the unedited text.)
Next, let’s move on to,
from gtts import gTTS
from playsound import playsound
...
def speak(audioString):
# print(audioString)
tts = gTTS(text=audioString, lang='en-uk')
tts.save("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
Here we’re are importing the gTTS module and using it to turn an input “audioString” into a sound, saving that sound, then playing that sound… Due to the lack of code here, I’m just going to leave it at that. For more on gTTS, check out: gTTS.
Moving on,
import speech_recognition as sr
...
def recordAudio():
# Record Audio
r = sr.Recognizer()
with sr.Microphone() as source:
#r.adjust_for_ambient_noise(source)
print("I'm listening")
audio = r.listen(source)
# Speech recognition
data = ""
try:
data = r.recognize_google(audio)
if data == "end program":
exit()
print("You said: " + data)
except sr.UnknownValueError:
speak("Can you please repeat that")
recordAudio()
except sr.RequestError as e:
speak("Can you please repeat that?".format(e))
recordAudio()
return data
Here we start by importing the speech recognition module as sr. We then start a new instance of Recognizer, “r,” and initialize the microphone as “source.” Passing “source,” we listen to it via “r.listen()” which returns our audio data, “audio.” This is where is get’s a bit sticky… We have to try and pass “audio” to “r.recognize_google()” to convert our speech into text, “data”; but, what do we do if we run into any errors. To handle this problem we have to use a try/except. With that said, it seems obvious that with every exception call, we should want to inform ourselves that there was a problem and recursively start the process back over again by calling “recordAudio()” And finally we return “data” so that the program can use those verbals inputs outside of “recordAudio().”
From here I assume the reader can follow the code, for Pt1. With that said, if there are any questions, feel free to ask!
Moving on to Pt 2. the facial recognition base code:
As I already mentioned the base code in Pt 2. is not exactly what we will be using in the assistant… but it’s close. I will explain the differences and post the “correct” code somewhere below.
So, to start, let’s take a moment to consider what it is we are trying to do. We want to take in an image(frame of a video) and search it for a face. But then we need to know if it finds one and if what it found is actually a face. So… to help us verify if the code is working correctly, we will need a collection of images with and without faces to feed to it as a test. It will then scan them for faces, place a box around any face(s) it may find, and save these new images as “result_’#’.jpeg.” With that, let’s take a look at the code.
i = 1
while i < 5:
title = "faces/" + str(i) + ".jpeg"
...
i += 1
In my particular case, I only used 4 test images, each located in the file “faces” and named “i.jpeg,” where i ∈ {1,2,3,4}. So here we have a while-loop to go thru each image and store their locations in the string “title.”
Next, we read the image in and assign it to the variable “image” using the function cv2.imread(); which we can use via importing the cv2 module.
import cv2
i = 1
while i < 5:
...
image = cv2.imread(title, 1)
...
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
I should note, the number 1 in our function here means that we want to read the image in as a color image. We then convert this image to gray scale via cv2.cvtColor(), and label it “gray.”
In this next part, we use something called a Haar Cascade to help us find our faces. I’m going to skip over an explanation for what a Haar Cascade is/does; as I assume the reader has a passing understanding of what they are/do. If you don’t, I suggest here as a starting place.
import cv2
i = 1
while i < 5:
...
face_cascade = cv2.CascadeClassifier('haarcascade/haarcascade_frontalface_alt.xml')
...
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
Here we use “cv2.CascadeClassifier()” to load “haarcascade_frontalface_alt.xml” as our cascade object and label it “face_cascade.” Next we have our cascade object run “detectMultiScale()” on our image “gray.” What we get in return is, “a list of rectangles”(http://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html) when a face is detected.
Finally, we have the following bit of code:
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.putText(image, "Image: " + str(i), (0, 10), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 2, 8, bottomLeftOrigin = False)
result = "results/result" + str(i) + ".jpg"
cv2.imwrite(result, image)
Let’s break this down in order,
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
goes thru and draws a rectangle around our face(s) in the original image, in blue with a line width of 2. Then we have,
cv2.putText(image, "Image: " + str(i), (0, 10), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 2, 8, bottomLeftOrigin = False)
which adds a label to the top left corner of the image, “Image: #” in red. And finally,
result = "results/result" + str(i) + ".jpg"
cv2.imwrite(result, image)
saves our new image as “result#.jpg.”
Now, about those changes… Instead of,
image = cv2.imread(title, 1)
We want to use,
retv, vid = video_capture.read()
retv is just a boolean, so it’s “vid” that “replaces” the variable “image.” In short, the code should read something like this:
#######################################################################################################################
# [2]
#
# Author:
# Matt Tucker
#
# Date:
# 26Aug2017-26Aug2017
#
# Description:
# The following is only part of a chatbot that will analyze visual information to identify users, create user
# profiles, imitate a personality based on user, while also acting as a virtual assistant via executing
# a handful of basic commands.
#
# This particular part handles the facial recognition procedure.
#
#######################################################################################################################
import cv2
import time
face_cascade = cv2.CascadeClassifier('haarcascade/haarcascade_frontalface_alt.xml')
video_capture = cv2.VideoCapture(0)
while True:
# Captures video frame by frame
retv, vid = video_capture.read()
gray = cv2.cvtColor(vid, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
print str(len(faces))
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(vid, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(vid, "Video: " + str(time.localtime()), (0, 10), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 2, 8, bottomLeftOrigin = False)
# Display the results
cv2.imshow('Video', vid)
cv2.waitKey(1)
You’ll probably notice I changed the label in the top left and added to the last two lines. On the issue of the label, I honestly did that just cause. The last line, however, is incredibly important as it acts as a delay allowing each frame to be updated.
Pt 3 the chatbot section.
I should first let you know, this has been the hardest part of the code thus far; and, I am still very unhappy with it. As of right now, I am using the ChatterBot API, the Cornell Movie-Dialogs Corpus, and the scripts from Shakespear’s plays that came with Natural Language Tool Kit(NLTK). In all, there are 229,336 lines of conversation for our chat bot to learn from. And I have rebuilt the program to train on about 5% of it, so… roughly 11,466 lines(the actual number is 11,432 for anyone keeping score) which took roughly 2.5mins. Unfortunately, it would appear that the time it takes to run the training session is nonlinear with the number of lines it is given. Evident by the fact that it was much slower training as it approached completion, which around 2.5 days… that compared to the 2.5mins. If I had to guess, it’s exponential… That said, it took the computer about a min to respond to “how are you.”
Traditionally the idea behind an AI chatbots is:
if given a set of initial rules/conditions for how language works, a program should be able to “learn” how to “respond” to some “input” by giving it sufficient training data. In the case of ChatterBot
With that, in the case of the code, I have prepared we see a bit of a twist on that. Instead of giving the bot a set of initial rules/conditions, it runs thru the training data looking for correlations between “statements” and the corresponding “response.” It then uses that data to decide which of the learned responses is most appropriate to respond to the user’s input with. In this way, the chatbot feigns a conversation. Here is the current version of the chatbt base code:
#######################################################################################################################
# [3_3]
#
# Author:
# Matt Tucker
#
# Date:
# 11Aug2017-26Aug2017
#
# Description:
# The following is only part of a chatbot that will analyze visual information to identify users, create user
# profiles, imitate a personality based on user, while also acting as a virtual assistant via executing
# a handful of basic commands.
#
# This particular part handles the chatbot procedure.
#######################################################################################################################
from playsound import playsound
from gtts import gTTS
import speech_recognition as sr
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
chatbot = ChatBot("Frank", logic_adapters=[{"import_path": "chatterbot.logic.BestMatch",
"statement_comparison_function": "chatterbot.comparisons.levenshtein_distance",
"response_selection_method": "chatterbot.response_selection.get_first_response"}])
# [1]
# Responsible for vocalising responses
def speak(audioString):
print(audioString)
tts = gTTS(text=audioString, lang='en-uk')
tts.save("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
# [1]
# Responsible for "listening and returning the users comments
def recordAudio():
# Record Audio
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
print("I'm listening")
audio = r.listen(source)
# Speech recognition
data = ""
try:
data = r.recognize_google(audio)
if data == "end program":
exit()
print("You said: " + data)
except sr.UnknownValueError:
speak("Can you please repeat that")
except sr.RequestError as e:
speak("Can you please repeat that?".format(e))
return data
# Trains ChatBot
def train():
val = input("Enter a value (0-319): ")
chatbot.set_trainer(ListTrainer)
j = 0
k = 0
while k in range(320):
i = 0
print "k = " + str(k)
f_1 = open('/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/clean_trainingdata.txt')
for line in f_1:
# print i
if i % 320 == k:
j += 1
inp = line
oup = next(f_1)
print '\n' + '\n' + str(j) + "-- " + '\n' + str(i) + ": " + inp + oup + '\n' + '\n'
chatbot.train([inp, oup])
i += 1
f_1.close()
print '\n' + '\n' + '\n' + '\n' + '\n'
k += 45
# Responsible for creating conversation.
def chat():
while 1:
q = recordAudio()
response = str(chatbot.get_response(q))
speak(response)
train()
while 1:
chat()
As I am not yet happy with the code, I am going to hold off on explaining how it works… At least until I either build a version I am happy with or one I settle for.
The “final” result:
The code in its entirety… sort of. It still isn’t the best conversationalist, nor does it recognize a person. But, it does recognize if a person is present, how many, and can take commands. So it’s a start. Albeit a rather buggy start.
#######################################################################################################################
# [*] version 0.1
#
# Author:
# Matt Tucker
#
# Date:
# 21Aug2017-26Aug2017
#
# Description:
# The following is the amalgamation of the base codes. It is a chatbot program which recognizes when a person
# is present and behaves as an assistant.
#######################################################################################################################
from playsound import playsound
from gtts import gTTS
import speech_recognition as sr
from chatterbot import ChatBot
import re
import webbrowser
import os
import wolframalpha
import wikipedia
import smtplib
from time import ctime
import pyowm
from twilio.rest import TwilioRestClient
from PyDictionary import PyDictionary
import cv2
from chatterbot.trainers import ListTrainer
# Keys and other user specific information
name = "YOUR NAME"
pw = "Your Gmail Password"
add = "Your Gmail Address"
location = "Clarkesville, GA"
signature = '\n' + name + '\n' + "This was written via Matt Tucker's digital assistant, as ran by" + name
client = wolframalpha.Client("Get Your Own! :P")
owm = pyowm.OWM('Get Your Own! :P')
account = "Get Your Own! :P"
token = "Get Your Own! :P"
client1 = TwilioRestClient(account, token)
chatbot = ChatBot("Frank")
# [1]
# This is the function responsible for executing commands
def command(data):
# Request time
if "time" in data:
speak(ctime())
# Request map info
if "show me where a city is" in data:
speak("Sure thing Mathew, what is the name of the city?")
city = recordAudio()
speak("Now, what state is it in?")
state = recordAudio()
speak("Hold on Mathew, I will show you where " + city + ", " + state + " is.")
speak("chromium-browser https://www.google.us/maps/place/" + city + "," + state + "/&")
# Request data search
if ("google" or "search") in data:
data = data.split("Google " or "search ")
search = "".join(str(x) for x in data)
speak("Googling " + search)
url = "https://www.google.co.in/search?q=" + search + "&oq=" + search + \
"&gs_l=serp.12..0i71l8.0.0.0.6391.0.0.0.0.0.0.0.0..0.0....0...1c..64.serp..0.0.0.UiQhpfaBsuU"
webbrowser.open_new(url)
# Resquest calculations be done
if ("calculate" or "find") in data:
if "calculate" in data:
data = data.split("calculate ")
else:
data = data.split("find ")
search = "".join(str(x) for x in data)
speak("Calculating " + search)
try:
res = client.query(search)
answer = next(res.results).text
speak(answer)
except:
speak("Sorry, I was unable to get an answer for you")
# Request info from Wikipedia
if "tell me about" in data:
data = data.split("tell me about ")
search = "".join(str(x) for x in data)
speak("Searching...")
try:
res = (wikipedia.summary(search))
speak("Sir, I found " + data + " for you: " + res)
except:
speak("I was unable to find anything")
# Get weather
if "weather" in data:
data = data.split("weather")
search = "".join(str(x) for x in data)
if "today" in search:
fc = owm.weather_at_place(location)
w = fc.get_weather()
else:
fc = owm.daily_forecast(location, limit=3)
w = fc.get_weather()
client1.messages.create(from_='(507) 607-7398', to='(507) 382-0499',
body = ('\n' + "Here's the forecast you requested:" + '\n' + w.get_detailed_status()
+ '\n' + str(w.get_temperature('fahrenheit'))))
# Request an email be written and sent
if ("email") in data:
speak("Certainly sir, who would you like me this to?")
targ = recordAudio()
speak("What would you like to say in your email sir?")
mat = recordAudio()
mail = smtplib.SMTP('smtp.gmail.com', 587)
try:
mail.ehlo()
except:
mail.helo()
mail.starttls()
mail.login(add, pw)
mail.sendmail(add, targ, mat)
mail.close()
# Request definition, synonym, or antonym
if "definition" in data:
data = data.split("definition of")
search = "".join(str(x) for x in data)
dictionary = PyDictionary()
speak(str((dictionary.meaning(search))))
if "synonym" in data:
data = data.split("synonym of")
search = "".join(str(x) for x in data)
dictionary = PyDictionary()
speak(str((dictionary.synonym(search))))
if "antonym" in data:
data = data.split("definition of")
search = "".join(str(x) for x in data)
dictionary = PyDictionary()
speak(str((dictionary.antonym(search))))
# ToDO #########################################################################
# ToDO # #
# ToDO # Add dictation. Remember to offer a few locations to store file. #
# ToDO # #
# ToDO #########################################################################
# Request a program be opened, use similar process to take down dictations in .txt file but it will nee a seperate
# calling to recordAudio for what it types.
if "open" in data:
data = data.split("open ")
program = "".join(str(x) for x in data)
speak("Opening " + program)
# Special note, use: os.system("open -a path/program.app") to open program so it should look like:
# if "name" in program:
# os.system("open -a path/name.app")
if "iTunes" in program:
os.system("open -a program.app")
if "Matlab" in program:
os.system("open -a MATLAB_R2017a.app")
if "VLC" in program:
os.system("open -a program.app")
if "slicer" in program:
os.system("open -a Slic3r.app")
if "pycharm" in program:
os.system("open -a 'PyCharm CE.app.app'")
if "ip scanner" in program:
os.system("open -a 'IP Scanner.app'")
if "Arduino" in program:
os.system("open -a Arduino.app")
if "eclipse" in program:
os.system("open -a Eclipse.app")
if "AutoCad" in program:
os.system("open -a 'AutoCAD 2016.app'")
if "terminal" in program:
os.system("open -a Terminal.app")
if "latex" in program:
os.system("open -a texmaker.app")
# Opens a file that acts as a list of impromptu commands
if "new command" in data:
speak("Remember, you have to type this for yourself. I can't type it for you.")
os.system("open -a '/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/command.txt'")
# Searches file of impromptu commands for correct command
else:
coms = open("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/command.txt", "r")
for line in coms:
if re.match(data, line):
os.system(next(coms))
else:
speak("I'm sorry, I can't do that.")
coms.close()
# [1]
def clean_text(text):
text = re.sub(r"<u>", "", text)
text = re.sub(r"</u>", "", text)
return text
# [1]
# Responsible for vocalising responses
def speak(audioString):
print(audioString)
tts = gTTS(text=audioString, lang='en-uk')
tts.save("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/audio.mp3")
# [1]
# Responsible for "listening and returning the users comments
def recordAudio():
# Record Audio
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
audio = r.listen(source)
# Speech recognition
data = ""
try:
data = r.recognize_google(audio)
if data == "end program":
exit()
print("You said: " + data)
if "I need help" in data:
command()
except sr.UnknownValueError:
speak("Can you please repeat that")
recordAudio()
except sr.RequestError as e:
speak("Can you please repeat that?".format(e))
recordAudio()
return data
# [2]
# Responsible for reporting the presence of a face or faces
# This will later be used to report any change in the number of individuals so as to improve the chat function
def recognition():
face_cascade = cv2.CascadeClassifier('haarcascade/haarcascade_frontalface_alt.xml')
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, vid = video_capture.read()
grayvid = cv2.cvtColor(vid, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(grayvid, 1.1, 5)
return str(len(faces))
# [3]
# Responsible for creating conversation.
def chat():
while 1:
q = recordAudio()
if q == "I need your help":
command(recordAudio())
if q == ("good bye" or "later"):
speak("Good bye!")
break
else:
response = clean_text(str(chatbot.get_response(q)))
speak(response)
#
def _init_():
num = recognition()
if num != 0:
speak("Hello!")
chat()
else:
_init_()
# time.sleep(1)
playsound("/Users/Tuck/Documents/PyCharm_PythonPrograms/ChatBot_Test/srcs/Computer_Magic-Microsift-"
"1901299923.mp3")
while 1:
_init_()
So, as I pointed out before there are still several features I’d like to eventually include into this project. For example, an SQL database that holds user data( e.g. name, age, gender, last conversation topic, personality metric/ranking). I’d also like for the Assistant to “recognize” individuals(which would inform it whom to pull data for to aid the chatbot portion of the code), as well as improve the chatbot portion of the code.
As a whole though, I’ve got to say, I’m kind of happy with this. The code listens for an initialization phrase, then for either a command phrase, exit command or general conversation and operates accordingly; but only if it recognizes a person is “present.”
I’d say this is off to a good start when compared to where I plan to take this in the future.
So, till next time!
Things I plan on changing:
- Build my own Chatbot, don’t use ChatterBot
- Use NLTK to clean training data
- Look into multithreading/parallel processing
- AI to help code recognize intent so voice command can feel more “fluid”… As it is, this is a very “dumb” design. In short, this UI SUCKS!
